Schema as the Core of Reliability
Most AI memory systems are still built around one core assumption: memory is mainly a retrieval problem.
Sometimes that takes the form of classic vector RAG - store text, embed it, retrieve similar chunks later. Sometimes it shows up in agentic systems that “remember” by endlessly appending observations, tool outputs, prior decisions, and working context into prompts, then compacting or summarizing that history when the context window fills up. And sometimes it appears in more advanced Graph RAG systems that add structure to retrieval by making relationships explicit.
These are different approaches, and some are meaningfully better than others.
But they still share the same underlying pattern: memory is stored largely as unstructured or semi-structured context, and correctness is reconstructed later.
That works well for one class of memory requests: thematic recall.
What were we discussing about this project? What direction were we leaning? What was the general context around this decision?
For those questions, approximate retrieval is often enough.
But operational memory is not just thematic recall. Once memory becomes an input to decisions, workflows, or automation, the requests change.
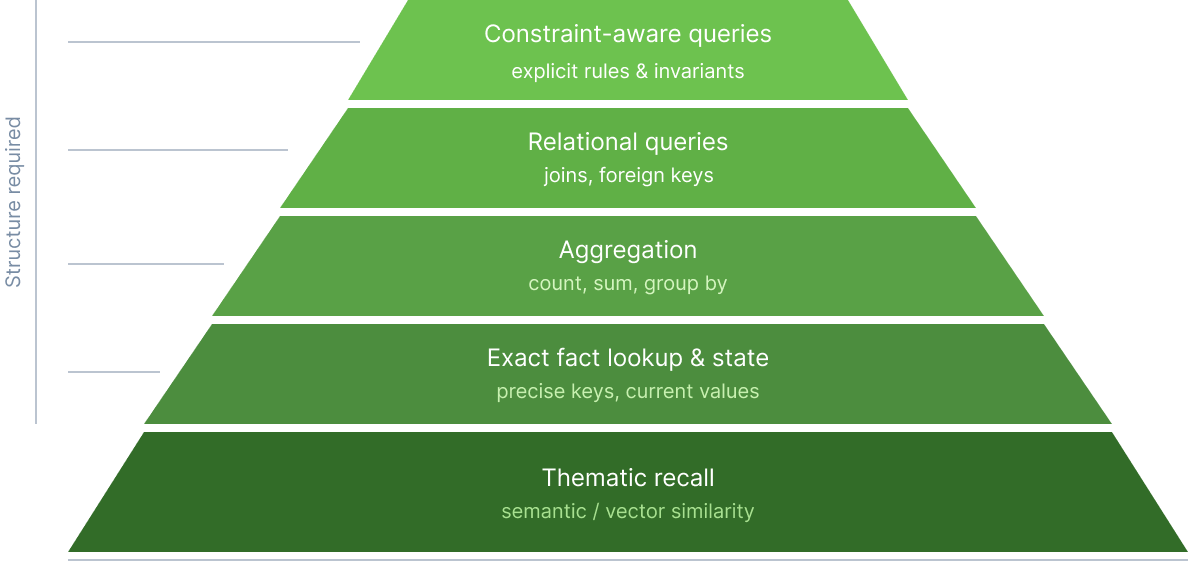
Now the system is being asked: What timeout did we set? Which vendor did we choose? What is the latest status? Which users reported an issue after release X? Which entities are related to this incident? Which expected facts are missing? How many times has this happened in the last month?
These are not all the same kind of query. Some are exact lookups. Some are state queries. Some are aggregations. Some are relational. Some depend on exclusions, constraints, or explicit unknowns.
And that is the real dividing line: different memory request types demand more than semantic similarity.
Search can recover context. Memory must support facts.
Section titled “Search can recover context. Memory must support facts.”The problem is not that retrieval is useless. It is that retrieval alone is not enough.
If memory is stored as text, summaries, or compacted prompts, every read becomes a fresh act of interpretation. The model has to parse prose, infer what matters, resolve ambiguity, and reconstruct the facts from narrative. The same history can produce slightly different answers depending on what was retrieved, how it was compressed, or how the model interprets it in that moment.
That is the core weakness of both vector-style memory and prompt-compacted memory.
Agentic systems often appear different because they do not always rely on semantic search. Instead, they carry memory forward by repeatedly appending context and compressing it over time. But the underlying issue is the same. Memory is still living as text. Low-salience but high-importance details can be merged, blurred, or dropped during summarization. Then later, the model is expected to recover exact facts from an approximate narrative trace.
Reliable memory cannot depend on repeated reinterpretation.
It has to be able to retrieve facts as facts.
Graph RAG is a real step forward - but not the endpoint
Section titled “Graph RAG is a real step forward - but not the endpoint”It is also important to be fair about what already exists.
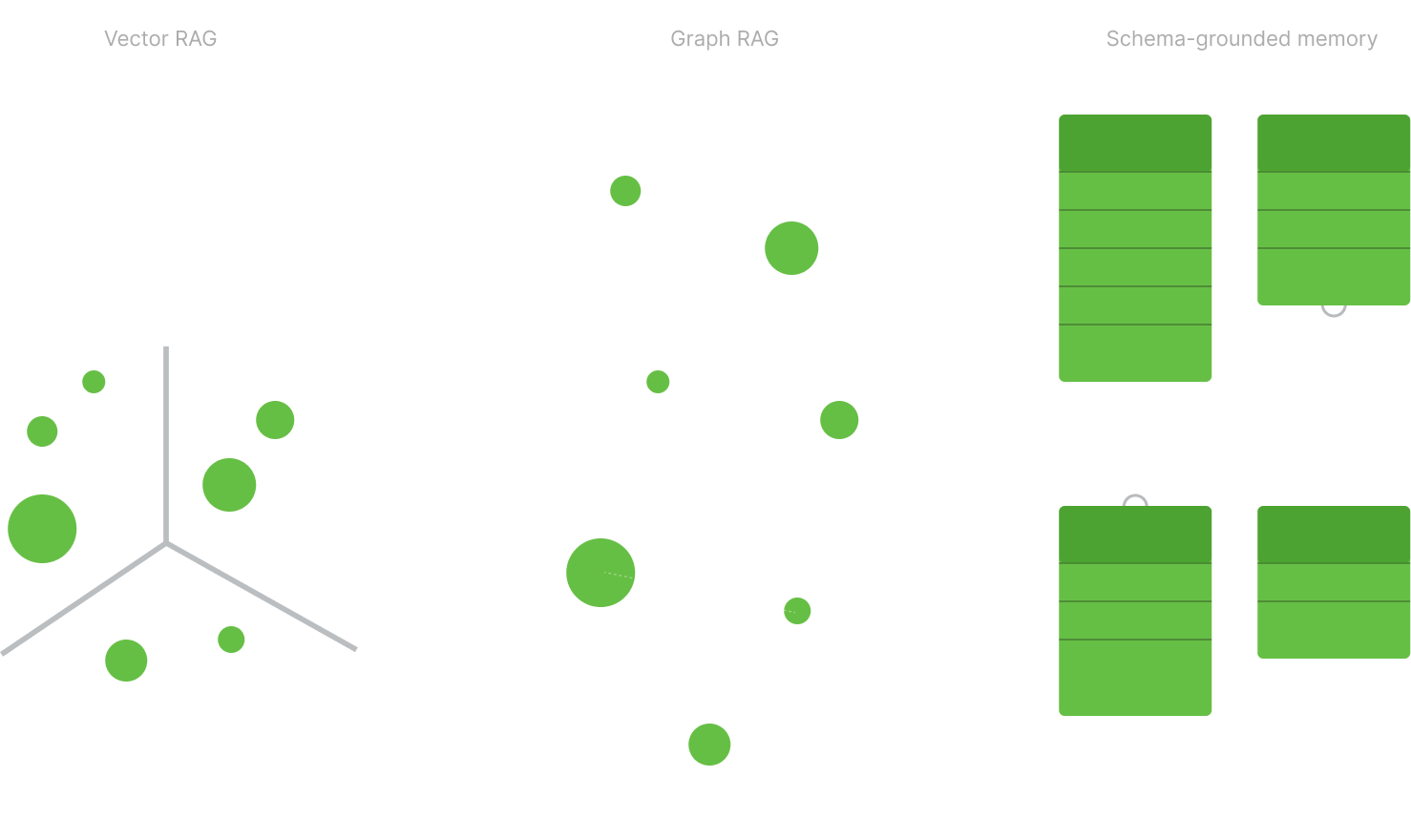
The world is not just simple vector databases and chunk retrieval anymore. Graph RAG and related approaches add meaningful structure. They make relationships more explicit, improve multi-hop reasoning, reduce some ambiguity, and often outperform flat retrieval when questions depend on connected entities or linked context.
That matters.
But Graph RAG still usually improves how the system navigates memory more than how memory itself is governed.
In many graph-based systems, the nodes or leaves still resolve to text fragments, summaries, or embeddings. The graph helps the system find related information, but it does not necessarily define what must be remembered, what counts as a valid fact, whether two records should be merged, whether a missing value is truly unknown, or whether a retrieved answer violates a constraint.
In other words, it brings more structure to retrieval, but not enough structure to guarantee reliable factual memory.
That is the gap schema fills.
Facts need shape
Section titled “Facts need shape”If memory is going to answer operational questions reliably, facts cannot remain buried inside text.
They need structure.
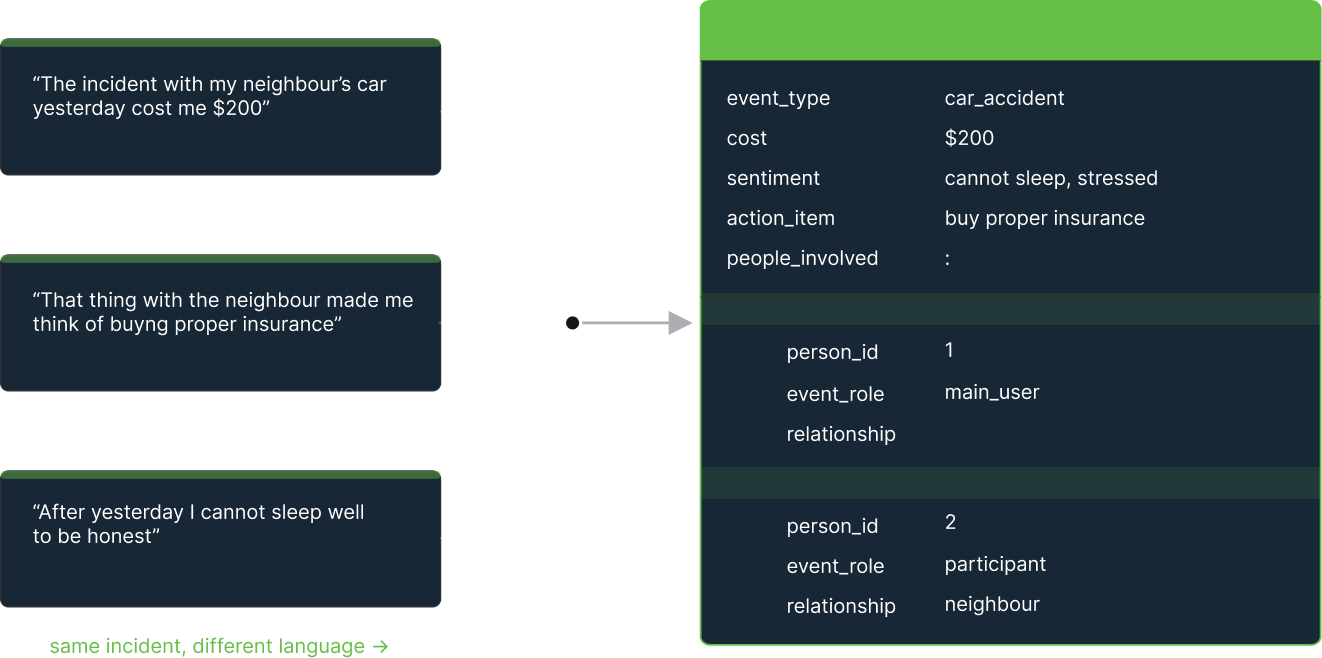
A memory system has to know when two things are the same thing. It needs deduplication so the same customer, decision, incident, or requirement is not stored in slightly different forms across time. It needs types so a date is understood as a date, a state as a state, and an identifier as an identifier. It needs relations so facts connect to the entities and events they belong to. And it needs constraints so the system can reject ambiguity instead of smoothing over it with a plausible guess.
This is what turns memory from stored language into usable knowledge.
Without structure, ambiguity is not an edge case. It is the default. The same entity gets duplicated. The same fact gets phrased three ways. A stale value and a current value sit side by side in narrative history. The model has to guess which one matters now.
With structure, memory becomes much more precise. Facts become addressable. State can be updated explicitly. Queries can filter, count, compare, and join over remembered information instead of re-deriving it every time from prose.
That is why different memory request types matter so much. The moment you need exactness, statefulness, aggregation, relations, or explicit absence, memory needs more than retrieval. It needs shape.
True observability and control require structure
Section titled “True observability and control require structure”This is also where observability becomes real.
If memory is mainly chunks, summaries, or prompt history, you can inspect pieces of the process, but not the contract itself. You may see what was retrieved. You may see what the model answered. But you still cannot clearly inspect what was stored, why it was stored, what changed, what failed validation, or where a specific answer actually came from.
Structured memory changes that.
Once memory is schema-grounded, records can be typed, versioned, validated, diffed, and linked to provenance. Unknowns can be explicit. Conflicts can be surfaced. Invalid writes can fail loudly. State changes can be tracked as state changes instead of silently blending into narrative history.
That is the difference between black-box recall and inspectable infrastructure.
And it is not just about debugging. It is also about control. A reliable memory layer has to make clear what should be remembered, what should be ignored, what requires confirmation, and what must never be guessed. That is very difficult to do with unstructured memory alone. It becomes much more tractable when the system is operating against a schema.
The best way to tell memory what matters is schema
Section titled “The best way to tell memory what matters is schema”This leads to the practical question underneath all of it: how do you tell memory what and how to remember?
One answer is prompting.
And prompting does matter. In fact, a large part of today’s agentic memory systems depends on prompts - prompts to summarize, prompts to compact context, prompts to decide what to retain, prompts to extract salient details, prompts to rehydrate compressed memory later.
But prompts are soft instructions. They are situational. They depend on wording, context, and the model’s interpretation in the moment. They are useful, but they are not strong enough to serve as the core contract for reliable memory.
A schema is.
A schema is the strongest prompt memory can have - because it does not merely suggest what matters, it defines it.
It says which entities exist, which fields matter, which relations are valid, which values are allowed, what counts as missing, and where the system must abstain instead of guessing. It survives paraphrase. It can be tested. It can be versioned. It can be observed. It can be enforced.
That is why schema-based memory is so powerful. It turns intent into an explicit, durable interface between the world and the memory layer.
Prompts still play an important role, but their role becomes clearer inside a schema-grounded system. They help detect objects, extract candidate fields, resolve links, and retry failed writes. But they operate inside a governed structure rather than replacing it.
The result is a memory system that does not simply sound coherent. It behaves predictably.
Reliability starts at the memory layer
Section titled “Reliability starts at the memory layer”The deeper point is simple.
If AI systems are going to do more than recover context - if they are going to make decisions, trigger workflows, maintain state, and operate over long horizons - then memory cannot remain a fuzzy layer of retrieved or compacted text.
It has to become a governed system of facts.
That means going beyond semantic search alone. It means going beyond endlessly appended and summarized prompt memory. It means acknowledging the progress of Graph RAG while also recognizing its limits. And it means embracing deduplication, types, relations, constraints, provenance, and schema as first-class parts of the memory system.
Because at the moment memory has to answer not just what feels related, but what is true, structure stops being optional.
Schema is not decoration.
Schema is the core of reliability.