Should Agents Adapt to Systems - or Should Systems Adapt to Agents?
A lot of business logic is moving out of code and into prompts.
Things that used to be implemented as explicit rules, branching logic, and application code are now increasingly expressed in instructions, examples, and model reasoning. Routing, classification, extraction, prioritization, exception handling - more and more of it is being handed over to LLMs.
At the other end of the stack, very little has changed. Databases still store state. APIs still expose rigid interfaces. Infrastructure still expects exact inputs. Systems of record still need consistency, predictability, and maintainability.
Software is being pulled apart
Section titled “Software is being pulled apart”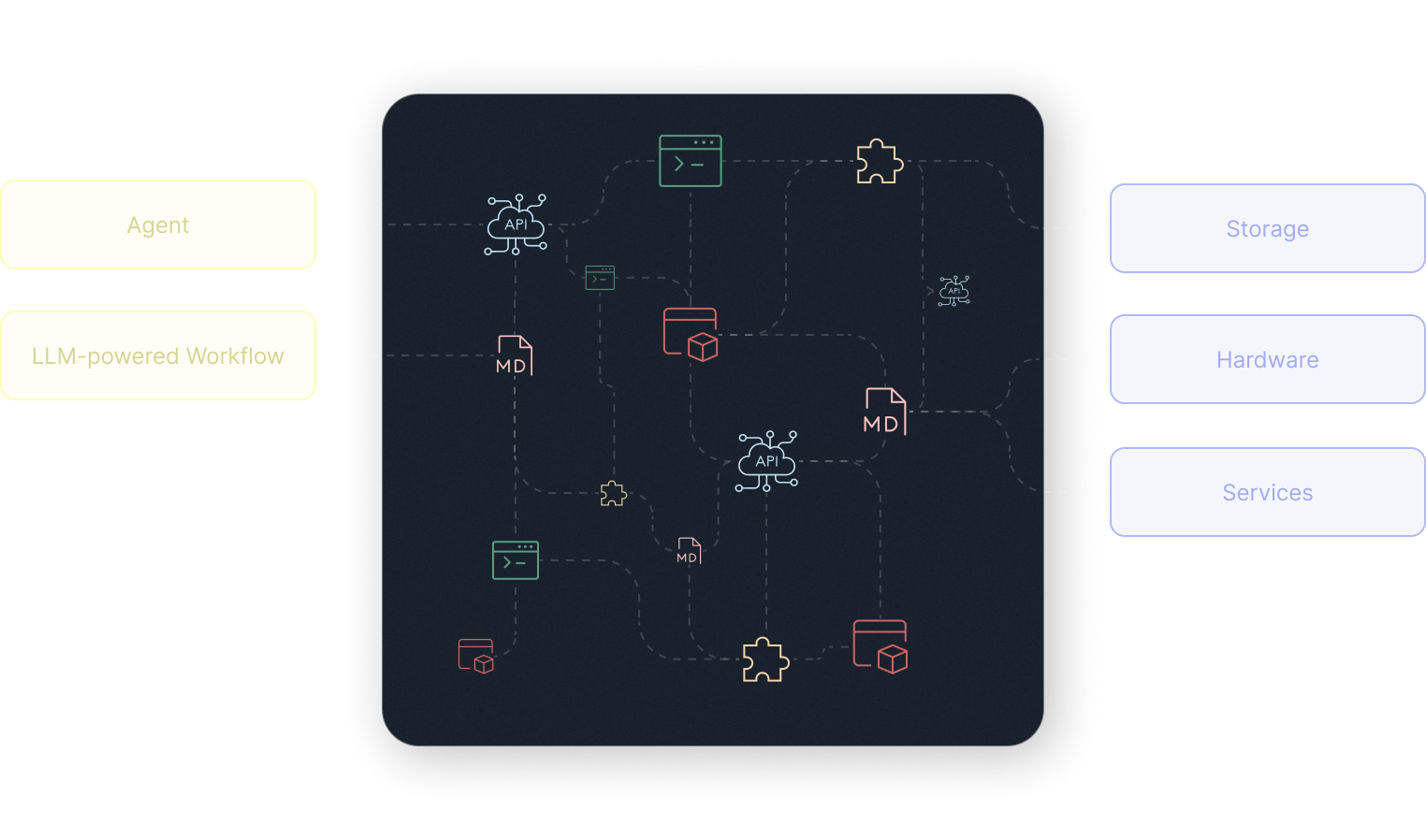
On one side, logic is becoming softer, more dynamic, and language-native. On the other, the systems that matter most remain structured, explicit, and unforgiving.
Between those two worlds, a large transitional layer is emerging: MCP wrappers, vibe-coded APIs, agentic .md files, skills, plugins, and all kinds of custom glue that help models operate real systems.
This layer exists because the fit is still awkward. Models are not yet fully self-sufficient tool users, and most systems are not yet designed to be used by agents.
Our guess is that much of this middle layer is temporary.
Over time, it will be absorbed from both sides.
One possibility is that models become good enough at reasoning, tool use, and code generation that they no longer need much custom guidance. They inspect interfaces, infer usage patterns, generate the missing wrappers for themselves, and operate systems with little more than credentials and permissions.
The other possibility is that systems themselves become more agent-native. Instead of exposing only low-level primitives, they start taking responsibility for more of the context needed to use them correctly.
MCP is only the beginning
Section titled “MCP is only the beginning”This is where MCP matters.
MCP is pushing the ecosystem toward standardization in how models discover and call tools. That is an important step. But tool selection and invocation are only the beginning. What actually makes system interaction work is all the system-specific context that still sits outside the call itself.
Storage is a good example.
A model may know that it should call a database tool, but using that tool correctly requires much more than invocation. It requires knowledge of schema, relationships, constraints, duplication rules, update semantics, and the existing state of the data. Today, that context is often pushed into prompts or custom scaffolding around the database interface. Developers end up recreating storage behavior outside the storage system itself.
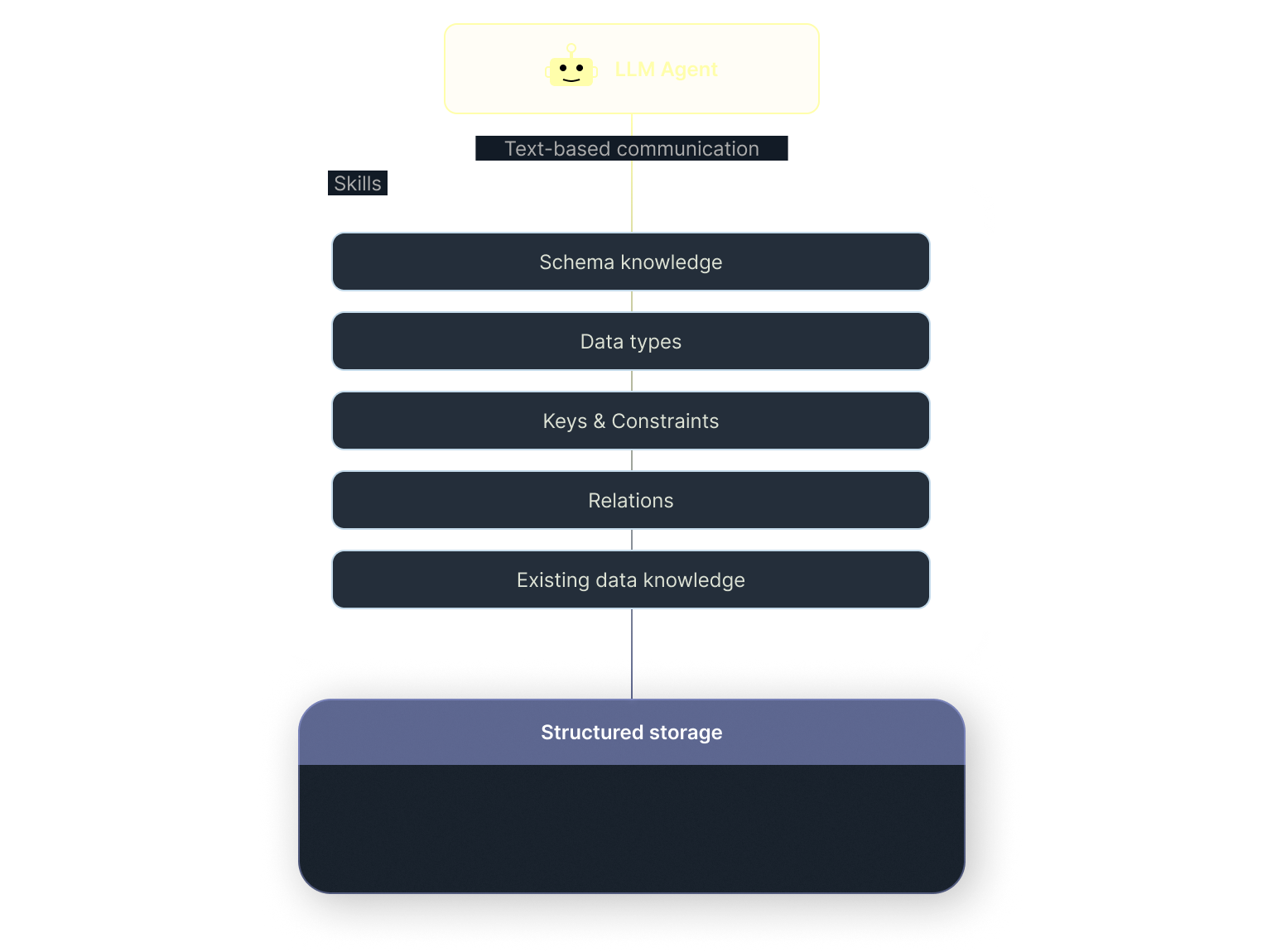
System knowledge should belong to the system
Section titled “System knowledge should belong to the system”But this is not really domain knowledge. It is system knowledge. And system knowledge should be owned by the system.
An agent should know what it wants to say and what actions it is allowed to take. The storage layer should handle the rest - mapping intent onto structured writes, deciding whether something is an insert or an update, resolving duplicates and relations, using existing context, and dealing with ambiguity in a reliable way.
That is the deeper adaptation many systems still need to go through.
Right now, a lot of agent infrastructure is really just a stopgap. We wrap systems in instructions, examples, helper functions, retrieval steps, and defensive glue so that agents can use them without breaking things. Some of that works. But it also spreads system-specific behavior across prompts and application code, making the whole stack harder to reason about, test, and maintain.
A more durable approach is to move that intelligence closer to the system itself.
If we want agentic software to be reliable, predictable, and maintainable, systems cannot remain passive endpoints behind thin wrappers. They need to expose higher-level semantics around what can be read, written, inferred, merged, and rejected. Not by becoming fuzzy, but by taking responsibility for the parts of interaction that are inherently system-specific.
The next abstraction layer
Section titled “The next abstraction layer”This would not be a new pattern in software. Storage interfaces have been evolving in this direction for decades. At the lowest level, developers had to think in terms of raw hardware and specific memory locations. Filesystems raised the abstraction, so the user no longer managed physical layout directly, but worked with named files and directories. Databases raised it further, letting applications work with structured records, relations, indexes, and query languages instead of file management. At each step, the interface improved by absorbing complexity that previously sat with the caller. The shift now happening with agents feels like the next step in that same progression.
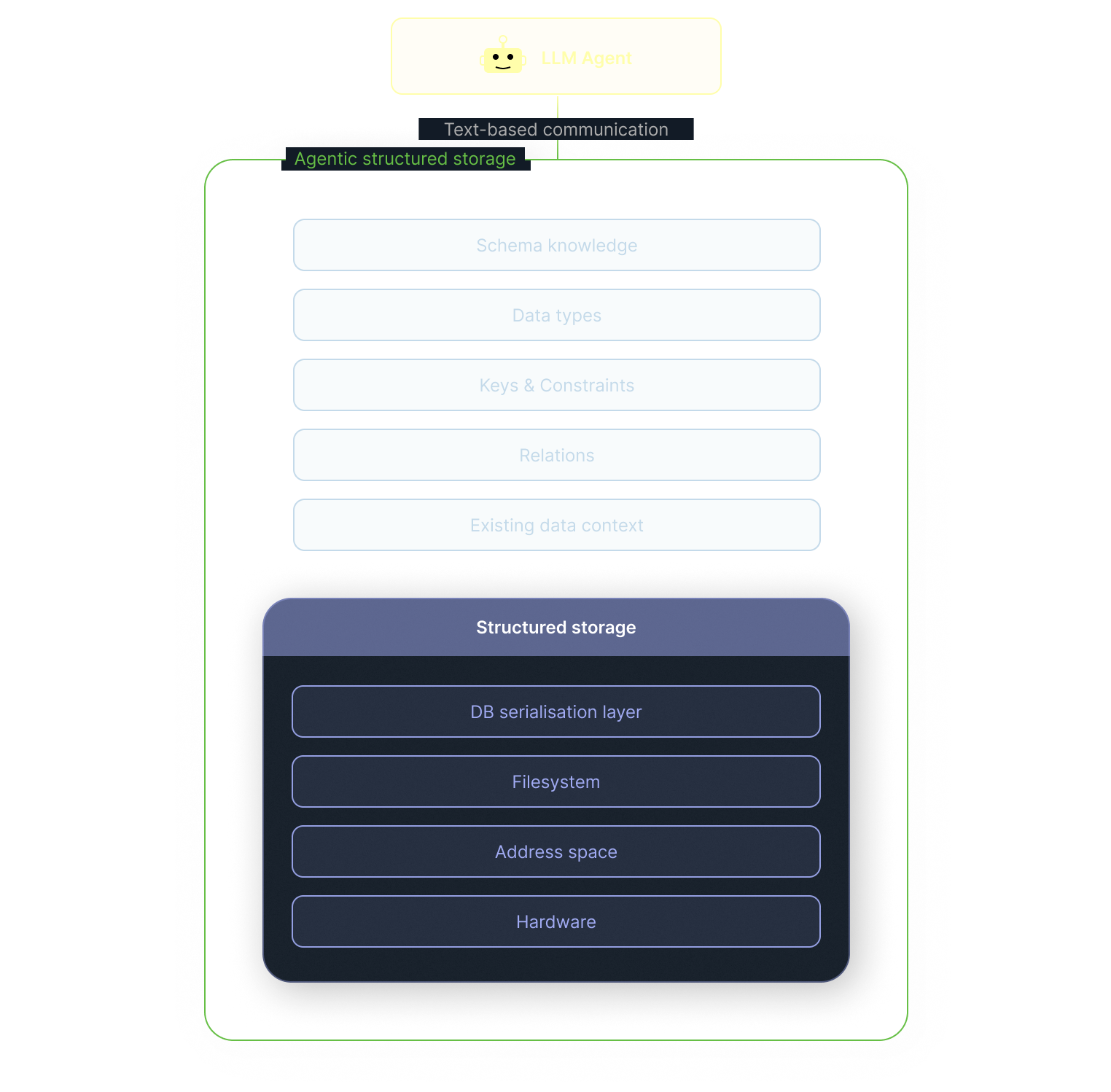
A cleaner boundary
Section titled “A cleaner boundary”This is the direction we are pursuing with xmemory.
We are building a way for agents to interact with structured, schema-based storage in natural language, while the storage layer takes responsibility for schema-aware extraction, relation resolution, deduplication, ambiguity handling, and the use of existing context. The goal is not to make storage less structured. It is to make natural language interaction with storage disciplined.
As more business logic moves into reasoning, systems will have to absorb more of the operational burden that agent developers currently carry in prompts and glue code.
The long-term outcome is probably not an endless pile of wrappers between models and systems.
It is a cleaner boundary.
Models should reason. Systems should own their semantics. And much of the awkward middle layer should eventually disappear.