Chasing AI memory SOTA: Beating the Benchmark, Missing the Point
66.88%, 80.1%, 85%, 90.79%, 93%, 91.69% and even 100% — what do all these numbers have in common?
They’re all state-of-the-art (SOTA) scores on various agentic memory benchmarks published at different times. The truth is that these numbers are not directly comparable, and they don’t necessarily reflect real-world performance. In this post, we’ll explore why chasing SOTA in memory benchmarks can be misleading, and what we should actually care about when evaluating memory systems.
The Measurement Problem: Recall Is Not Memory
Section titled “The Measurement Problem: Recall Is Not Memory”Most memory benchmarks are, at their core, thematic recall tests. A long conversation is stored. Later, a question probes whether the system can surface a relevant passage. Score well, and you are declared a capable memory agent.
This framing is useful when the downstream task is “did the user mention their dog’s name?” It is the wrong framing for the class of memory operations that actually break production systems:
- Single fact lookup —
What timeout did we set? - Aggregation —
What's the average budget mentioned by our customers over the last month? - State tracking —
What's the current status of the release? - Relational queries —
Which users reported errors after version X? - Negative / Exclusion queries —
Which courses are not starting next month?
You can read more on the topic in our white paper and blogpost.
These are not exotic edge cases. They are the bread and butter of any production-ready memory system. And virtually none of the standard benchmarks test them directly.
The deeper issue is architectural. When memory is implemented as embedded text chunks and similarity search, thematic recall is the natural capability. The system retrieves passages that are semantically near the query. It does not retrieve the current value of a field. It does not answer “has this ever been explicitly set to null?” reliably. It drifts toward plausible completion rather than evidence-grounded recall. Benchmarks that score on thematic proximity reward exactly this architecture — and hide its failure modes.
The chart below maps — qualitatively — how well popular benchmarks cover the memory functions that actually matter: what each one tests, what it quietly ignores, and why those blind spots pushed us to build our own datasets. We get into what those datasets look like later in the article.
Note: The benchmarks are not wrong. They measure what they set out to measure. The gap is between what they measure and what production memory systems are asked to do.
Existing benchmarks — a quick tour and overview of the gaps
Section titled “Existing benchmarks — a quick tour and overview of the gaps”We will discuss two of the most popular benchmarks in the space: LoCoMo and LongMemEval. Both are important steps forward, but both also have significant gaps when it comes to predicting real-world performance.
LoCoMo
Section titled “LoCoMo”LoCoMo (Long-term Conversational Memory) is probably the most cited benchmark in the memory space right now. It tests agents on long multi-session dialogues spanning up to 35 chat sessions, covering question types from single-hop retrieval to adversarial questions where the answer simply doesn’t exist in the data. Sounds rigorous. And in some ways it is.
The entire dataset is synthetically generated — virtual agents talking to each other, seeded with LLM-crafted personas and causal event graphs. Real conversations are messy, inconsistent, and full of ambiguity. LoCoMo conversations are… not. They’re clean, coherent, and structurally organized in ways that real human speech rarely is. That’s great for controlled evaluation. It’s terrible for predicting whether your system will survive contact with actual users.
Researchers at Letta demonstrated that you can hit 74% accuracy on LoCoMo by literally dumping the conversation history into a flat file — no sophisticated memory architecture, no vector database, no retrieval magic. Just a file. Which means that LoCoMo isn’t quite testing what we think it’s testing.
And the problems go deeper than synthetic data. In the appendix of our white paper, we call out a few concrete LoCoMo examples. In conv-30, the following questions illustrate how fuzzy the category system is:
{ "question": "What do Jon and Gina both have in common?", "answer": "They lost their jobs and decided to start their own businesses."},{ "question": "What is Gina's favorite style of dance?", "answer": "Contemporary"},{ "question": "What is Jon's favorite style of dance?", "answer": "Contemporary"}The issue is apparent here: the label set is not comprehensive enough to capture all relevant dimensions of the task. They also show practical ambiguity, since equally plausible interpretations can map the same question to different label categories.
Other items are worse because the label is not just ambiguous but incomplete. One question asks “What might John’s financial status be?” but the evidence provided does not support a definitive factual answer — it only suggests an inference:
{ "question": "What might John's financial status be?", "answer": "Middle-class or wealthy", "evidence": ["D5:5"]},{ "speaker": "John", "dia_id": "D5:5", "text": "It's definitely isn't, Maria. My kids have so much and others don't. We really need to do something about it."}Similarly, the benchmark asks whether Caroline would likely own Dr. Seuss books based on a comment about collecting children’s classics—again, inference rather than fact retrieval:
{ "question": "Would Caroline likely have Dr. Seuss books on her bookshelf?", "answer": "Yes, since she collects classic children's books", "evidence": ["D6:9"]},{ "speaker": "Caroline", "dia_id": "D6:9", "text": "I've got lots of kids' books- classics, stories from different cultures, educational books, all of that."}In both cases the benchmark is scoring a probabilistic inference, not retrieval of a stored fact. That is a reasoning task wearing a memory benchmark’s name tag. Add the reported label-error rate of about 6.4% (many of these errors we identified ourselves before deciding not to measure on LoCoMo), and you get a leaderboard where dataset ambiguity can matter almost as much as memory quality.
The most charitable interpretation: LoCoMo measures retrieval from synthetic data. The least charitable: it measures who has the most patient prompt engineer.
LongMemEval
Section titled “LongMemEval”LongMemEval (Wu et al., 2024, ICLR 2025) extends the evaluation surface meaningfully. Its 500 manually constructed questions cover five core abilities: information extraction, multi-session reasoning, temporal reasoning, knowledge updates, and abstention. The knowledge-update category is a genuine addition — it asks whether a system correctly supersedes stale information when a user revises a preference or corrects a prior statement.
The abstention category is also notable. A system that always produces an answer will score poorly on questions about information that was never provided. This tests a failure mode that matters in production: hallucination of a plausible but ungrounded answer.
LongMemEval’s scope is still conversational and QA-oriented. Scores are measured against free-text answers judged by an LLM evaluator. This means the benchmark is well-suited for assessing whether the right content is retrieved and surfaced, but it does not directly evaluate whether a memory system can answer structured queries, enforce consistency across fields, aggregate across records, or handle relational constraints. A RAG pipeline and a schema-grounded system can achieve similar QA scores through very different mechanisms — and only one of those mechanisms will behave reliably as state complexity grows.
There are label-related issues in LongMemEval datasets, too. There is a public issues log — kudos to the team for transparency here.
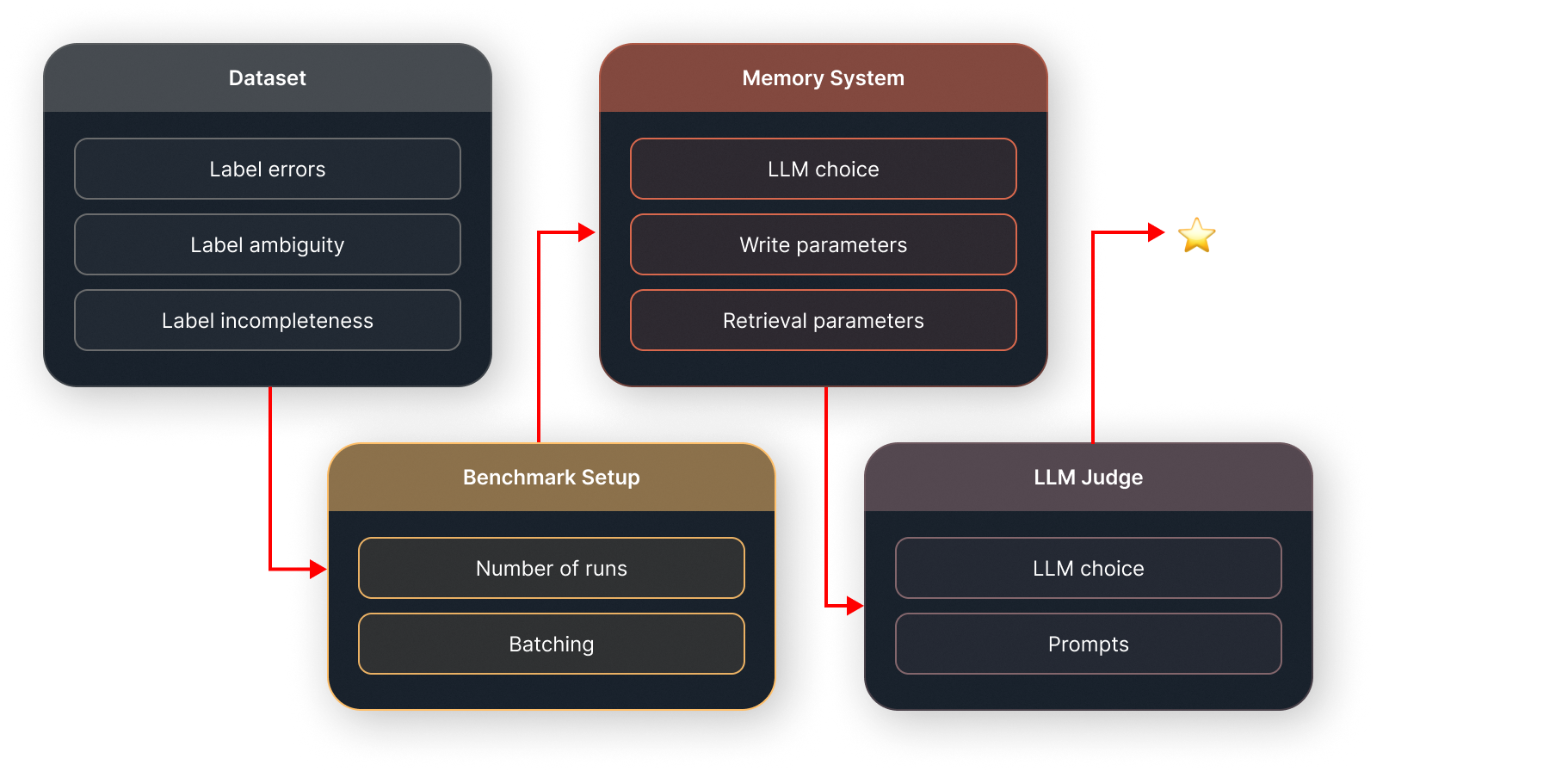
Benchmark setup, system configuration and reproducibility
Section titled “Benchmark setup, system configuration and reproducibility”When Emergence AI published their impressive LongMemEval results, a sharp-eyed developer noticed a hardcoded retrieval limit of k=42 — 42 chunks returned per query, no matter what. Tweaking that single parameter to a dynamic value shifted results noticeably. Cost went up 42%. The number on the leaderboard moved.
One hyperparameter. One number buried in a config file. Huge effect on the headline score.
Now consider that every team running these benchmarks makes dozens of such choices: which LLM backbone, which embedding model, which chunking strategy, what temperature, what prompt template, how data gets ingested. None of this is standardized. The result is that comparing two systems on the same benchmark is, to use a technical term, vibes-based.
LLM judges are part of this story too. In practice they are often unavoidable: once a benchmark asks open-ended questions over natural language, somebody has to decide whether an answer is correct, partially correct, or just plausible nonsense. But that doesn’t make vague labels acceptable. If the gold answer itself requires commonsense inference, or if a question could reasonably belong to several categories, then the judge is no longer just checking correctness — it is compensating for holes in the benchmark design. LongMemEval runs into related issues here as well: it mixes retrieval with reasoning, and even its GitHub repo has reports of label problems similar to LoCoMo’s. At that point, your score is partly a measure of memory quality and partly a measure of which judge model you used, how forgiving it was, and how much ambiguity it was asked to smooth over.
So, what does X% SOTA on these benchmarks actually mean?
Section titled “So, what does X% SOTA on these benchmarks actually mean?”Let’s be honest about what the number represents.
It means: on this dataset, with these hyperparameters, using this LLM backbone, graded by this judge, implemented in a way that may or may not be reproducible, we got this score.
That’s not nothing! It’s a useful data point in a controlled experiment. What it is not is a claim that the memory problem is solved, or that users will have a better experience, or that your system will perform better than a competitor’s in production. Moreover, results are often non-actionable from a product perspective, as it’s not clear what memory functions in your system could be implemented better.
The same number can mean wildly different things depending on:
- Whether the team optimized their prompts specifically for this dataset
- Whether they used a more powerful (and more expensive) backbone model
- Whether the benchmark’s synthetic nature flatters their architecture
- Whether the evaluation methodology can actually be reproduced.
Chasing AI memory SOTA is useful when it sharpens the product. It becomes noise when it is used as a substitute for product reliability.
Can we do better?
Section titled “Can we do better?”At xmemory, we care about benchmark performance, but we care more about what those numbers mean inside a product. A retrieval score on a narrow dataset is not the same thing as reliable memory in a multi-step workflow, in a customer-facing agent, or in a system that writes back into business logic.
That is why we look at memory quality through two lenses:
- Controlled evaluation, where we can compare systems fairly.
- Product metrics, where we measure whether memory actually improves outcomes for users and operators.
The second category matters more. Better memory should reduce task failure, improve personalisation, lower repetition, and increase confidence that the system is acting on the right facts.
In our white paper, we propose a few concrete targeted measurements to test these outcomes. Our datasets target both write and read paths in a memory system — correctness of the answer depends not only on retrieval capabilities but also on the ability to store and update information accurately. We published all the datasets here.
Extraction benchmark: where quality actually drops
Section titled “Extraction benchmark: where quality actually drops”One useful example is our extraction benchmark on the modified insurance-claims dataset from the Cleanlab structured-output benchmark. We report three levels at once: field-level F1, object-level accuracy (all fields in an object must be correct), and output-level accuracy (the entire claim output must be correct). The key pattern is consistent across systems: field-level scores are high, object-level is lower, and output-level is lower still. In other words, small per-field errors compound quickly as task complexity increases.

This is exactly why leaderboard headlines based only on retrieval or per-field quality can be misleading: product reliability depends on end-to-end correctness, not just local accuracy.
End-to-end memory functions benchmark: where architecture differences become visible
Section titled “End-to-end memory functions benchmark: where architecture differences become visible”Our end-to-end benchmark in the white paper is designed to test memory functions directly across four independent domain datasets — corporate, education, medical, and finance — with writes that include updates, deletions, renames, and relation changes, followed by read queries covering single-fact lookup, state tracking, relational joins, aggregation, and negative-exclusion cases. Evaluation is micro-averaged at the fact level across all domains. On this setup, xmemory reaches 99.15% precision, 95.12% recall, and 97.10% F1, while third-party systems land between 80.16% and 87.24% F1 (Zep 80.16%, Supermemory 80.49%, Mem0 graph 86.07%, Cognee 86.18%, Mem0 no graph 87.24%). The point is not that one stack wins one benchmark; it is that when you evaluate explicit state transitions and absence handling end-to-end, architecture differences become much harder to hide behind retrieval-only scores. Results obtained on this benchmark suggest missing or underdeveloped capabilities in a memory system, hence they are directly actionable for product development.

Real-world dataset: application-level memory under workflow pressure
Section titled “Real-world dataset: application-level memory under workflow pressure”To get closer to production behavior, the white paper also includes a real-world style Splitwise benchmark where each write is a natural-language expense event (who paid, how much, when, for whom) and reads require both retrieval and computation (balances, thresholds, participant-level rollups). On this task, xmemory reaches 95.2% accuracy, compared with 73.75% (Supermemory), 68.0% (Cognee), 59.1% (Mem0 graph), 54.9% (Mem0 no graph), and 25.7% (Zep). We also report that code-generated Markdown harnesses reached 12% and 40%, while customer-facing frontier-model application harnesses were around 92%. The takeaway is practical: once memory quality is measured inside an actual workflow, stable structured state and mutation handling matter more than evaluation in an artificial environment.
Conclusion: the number is real, the meaning is negotiable
Section titled “Conclusion: the number is real, the meaning is negotiable”SOTA benchmark numbers in agentic memory are not lies. They’re just… non-deterministic summaries of a specific experimental configuration, evaluated against noisy datasets, using LLM judges that introduce their own variance, on tasks that may not resemble what real users actually need.
Which is a long way of saying: take them seriously as one data point, and not at all seriously as a ground truth.
We’re in a field that is measuring itself against itself. The real question isn’t “are we beating last week’s leaderboard?” — it’s “are we building something that makes people’s work meaningfully better?”
That’s harder to measure. It’s also the only thing that matters.