Schema Evolution: Engineer Your Memory, Don't Just Store It
xmemory is built on schemas. It is not a drop-in, remember-everything box - and that is exactly where its power comes from. Structure is what makes memory reliable: a schema is an explicit, enforceable contract for what your memory must remember, what it may ignore, and which values it must never invent. That is what turns memory into a system of record rather than a guess - and it is why xmemory reaches 97.10% end-to-end F1 at 99.15% precision, against general-purpose baselines that land between 80 and 87%.
The schema is the best part of xmemory. This post is about the two things that make it effortless: how easy it is to start one, and how xmemory keeps it perfectly fit to your work - automatically - through schema evolution.
Schema is your control dial
Section titled “Schema is your control dial”A schema isn’t overhead you carry; it’s a dial you turn. At one end sits a loose, almost schema-less shape - an entity-attribute-value (EAV) store that captures facts flexibly while you are still learning a domain. At the other sits a fully normalized, third-normal-form (3NF) design: typed objects, fields, and relations, where every fact is precise, deduplicated, and directly queryable. You choose where on that dial to sit, and you can move along it whenever you like - because more structure buys more reliability. xmemory’s results show memory quality rising steadily as structure increases.
And you don’t hand-write any of it. Describe your use case in a guided chat and xmemory drafts the schema for you - objects, fields, and relations you can review and adjust on the spot - or let your own agent build it straight from the CLI. Either way it is inferred from what you already have: a narrow projection of your systems of record (CRM, ERP, ticketing, a warehouse), a sample of your historical data, or a plain description of the questions you want answered. Every path produces a working contract that delivers value from day one.
Best of all, you don’t maintain it. Keeping a schema in step with a changing business is ongoing work, so xmemory does it for you - not the other way around. That is what the schema evolution engine is for.
How schema evolution works
Section titled “How schema evolution works”Evolution keeps your schema fit by learning from how the memory is actually used.
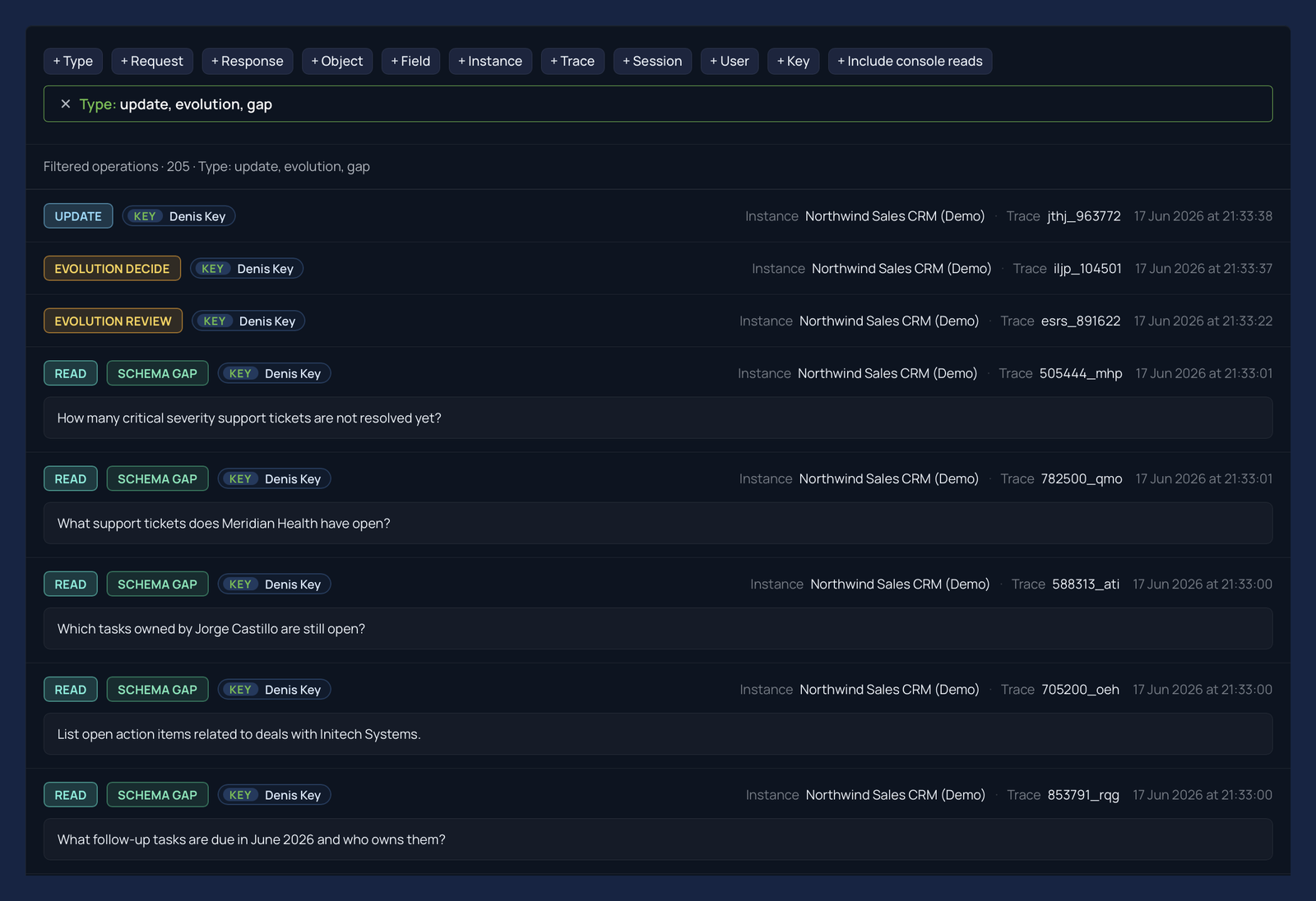
Signals from the read and write paths. The read path is the richest source of truth about what your schema should be. Every question your agents ask is direct evidence of what they need, and when a question reaches for something the schema doesn’t yet hold, that gap is precise signal - captured for free, without ever slowing the read down. The write path adds its own: recurring ambiguity, or values that don’t quite fit, point to where the contract can be sharpened. Together they give xmemory a continuous, low-cost picture of exactly how your schema should grow.
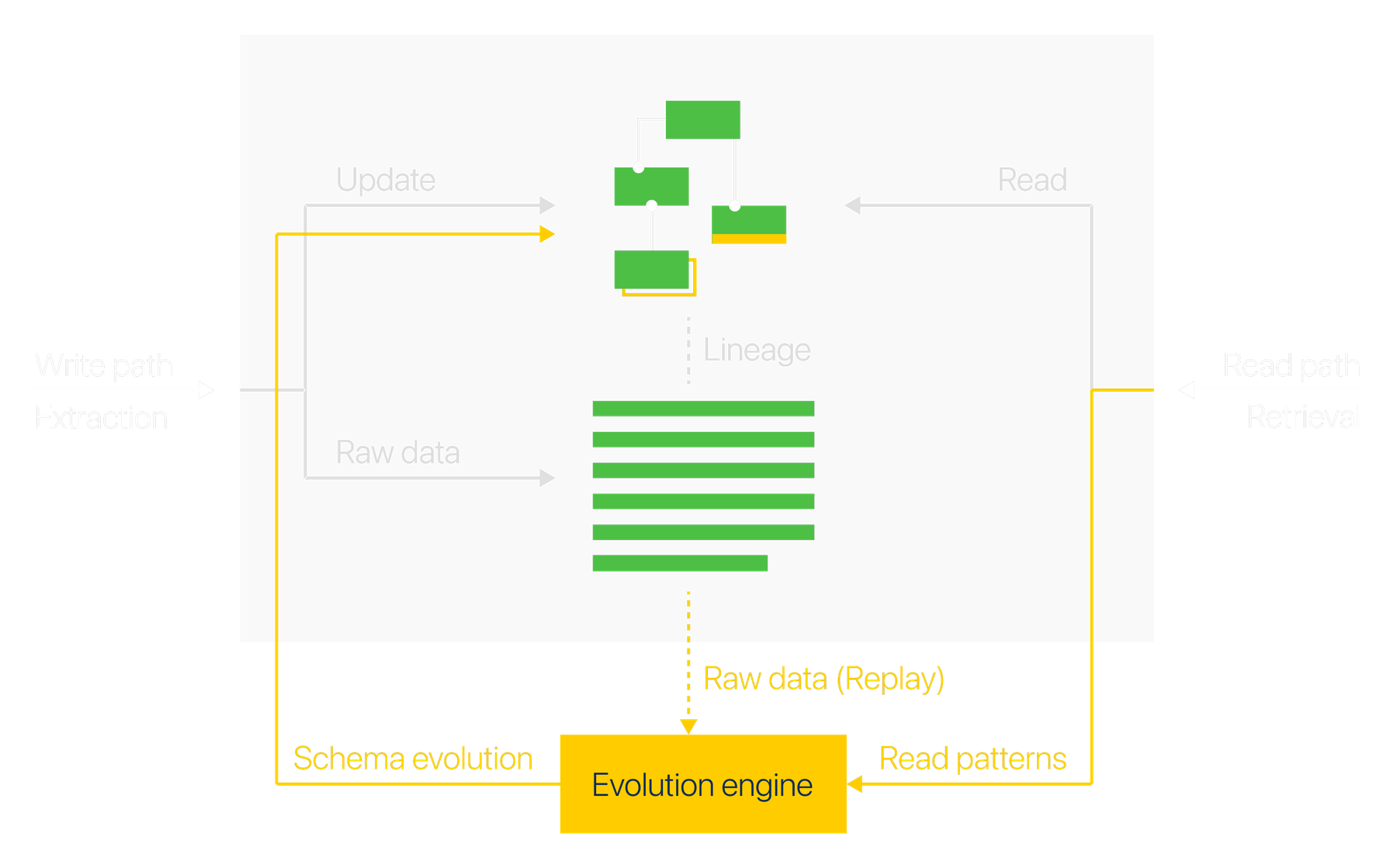
This is the loop at the heart of evolution - the same one we lay out in the xmemory whitepaper: usage flows into a schema engine, which turns observed demand into concrete schema changes on the write path, closing the loop between how memory is used and how it is structured.
A clear loop, with you in control. Recurring signals are consolidated into a few concrete, deduplicated proposals - a field to add, an object or relation the workload now needs - each carrying the evidence behind it: the real queries that asked for it, and how often.
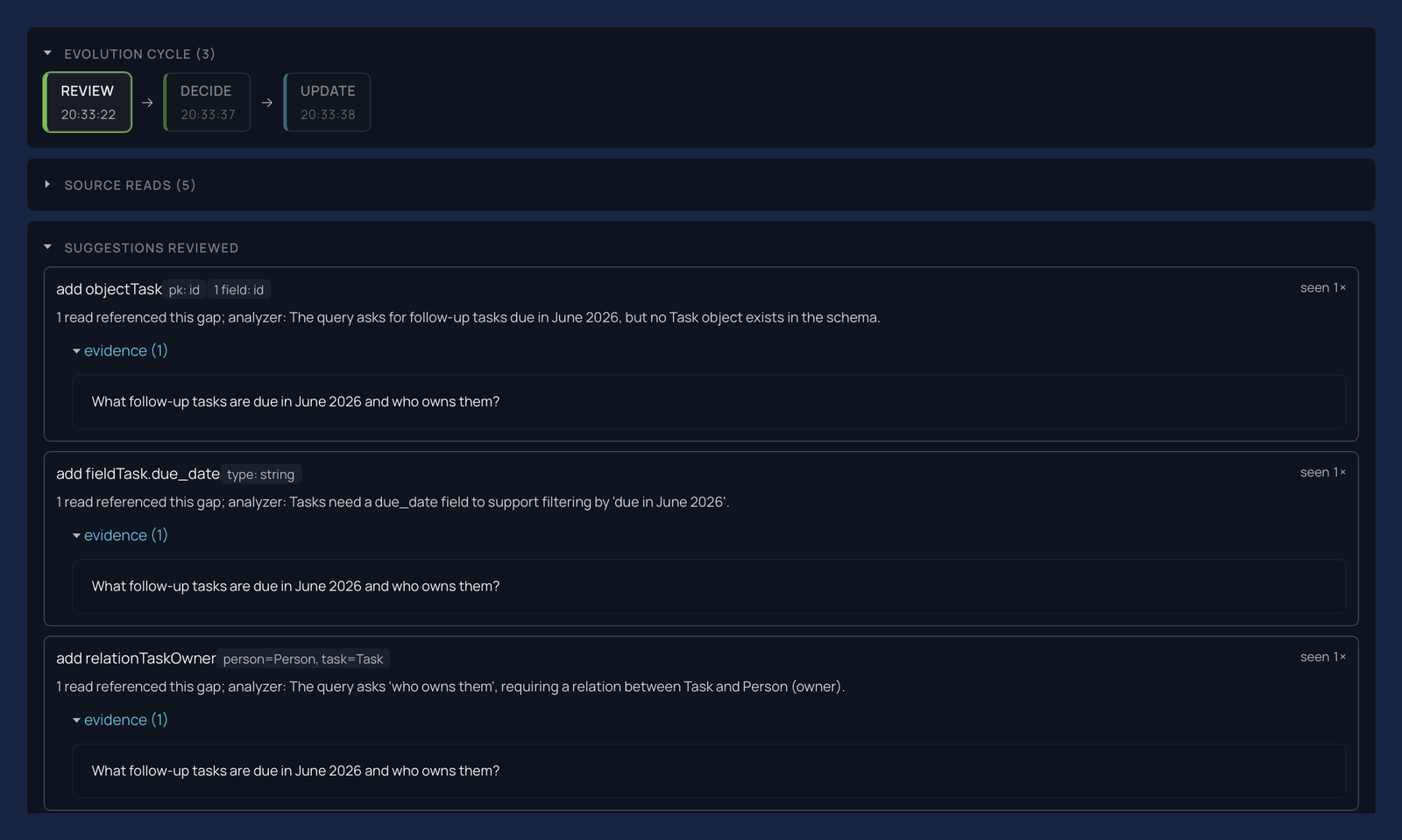
You review and decide - accept, refine, or defer, one change at a time. You can adjust a proposal before it lands, and rejecting one teaches the engine to stop suggesting it - and every proposal can be checked against the very questions it is meant to answer, so what lands is verified, not guessed. Each accepted change lands as a versioned migration: atomic, data-preserving (a rename is carried out as a rename, so every value is kept), and reversible. In the after-update diff, only what changed lights up green - the newly added object standing out against the existing schema it joins:
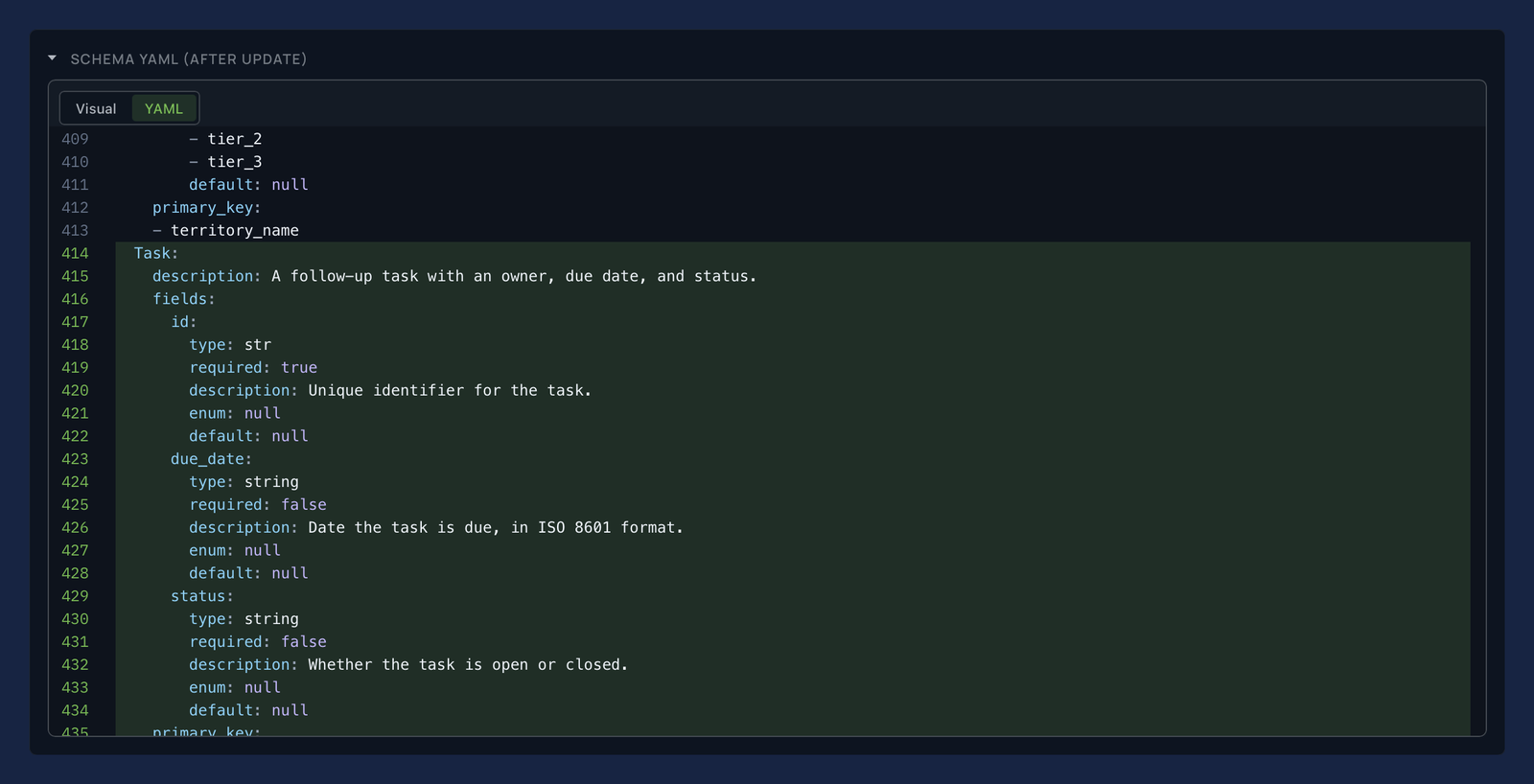
Data replay. Because interpretation happens once, on the write path, a migration can reach backward as well as forward. When the schema gains a field, object, or relation, xmemory replays your history through the same verified extraction and backfills the new structure for data you already hold - so a value that was always present becomes queryable everywhere, not just for new writes. And the replay is precise: rather than re-importing everything, it revisits only the history the change actually touches, so the cost of completing the past scales with the size of the change, not the size of your memory. Where a value genuinely was never there, it is recorded as an explicit unknown rather than invented - your memory stays honest about what it does and doesn’t know.
Autonomous evolution. Steering doesn’t have to be hands-on. Grant an agent the right permissions and it can run the loop itself - weighing the evidence behind each proposal and applying the changes that hold up - a genuine path to self-evolving memory, with you in oversight at all times.
Lineage and governance, for free. Every change is a versioned migration, so your schema carries its whole history: you can see exactly what changed, when, who - or which agent - approved it, and the evidence that justified it, and reconstruct or roll back to any earlier version on demand. Because evolution moves through concrete, testable migrations rather than quiet prompt edits, there is no prompt drift - every improvement stays explicit and accountable. The audit trail isn’t extra work you take on; it is a by-product of how evolution already works.
Why this is the future of memory
Section titled “Why this is the future of memory”Schema is the programming language for memory. Prose tells a model what happened; a schema tells memory what matters - precisely, declaratively, and once. It is a declaration of intent and an enforceable contract, not a soft instruction to be re-interpreted on every read. That is the difference between memory that sounds right and memory that is right.
It gives agents a short, explicit feedback loop. Structured reads and writes answer an agent immediately and unambiguously: this field exists, this value is required, this query has an answer - or an explicit unknown. A tight, explicit loop is what makes agents dependable, and it is exactly what systems should give agents instead of fuzzy glue.
It compounds. Because evolution is driven by what you actually read, your schema bends toward your use case and your vertical - it gets better the more you use it, tuned by real demand rather than guesswork. It only ever adds what evidence justifies and you approve, so it stays the minimal contract for your workload: your agents make the schema sharper without ever corrupting or bloating it. They stay on a leash; the schema stays clean.
This is what it means to engineer your memory rather than just store it. You start in minutes, you get a system of record from day one, and it only improves - the same discipline that produces 95.2% accuracy on real application workloads. And it is memory you can answer for: you always know what it remembers, how that has changed, and why - data governance as a side effect of doing memory well. The schema is the core of xmemory, and with evolution it is a core that keeps getting stronger the more you use it.